AI 最臭名昭著的 Bug 是什么?不是代碼崩潰,而是「幻覺」—— 模型自信地編造事實(shí),讓你真假難辨。這個(gè)根本性挑戰(zhàn),是阻礙我們完全信任 AI 的關(guān)鍵障礙。
大模型會(huì)有幻覺,這幾乎已經(jīng)成為一個(gè)常識(shí),讓每一個(gè)嚴(yán)肅使用大模型的人都不得不謹(jǐn)慎小心。OpenAI 也指出:「ChatGPT 也會(huì)產(chǎn)生幻覺。GPT-5 的幻覺明顯更少,尤其是在執(zhí)行推理時(shí),但幻覺仍然會(huì)發(fā)生。幻覺仍然是所有大型語言模型面臨的一大根本挑戰(zhàn)。」
盡管現(xiàn)在學(xué)術(shù)界已經(jīng)提出了各種各樣用來降低模型幻覺的方法,但目前尚未出現(xiàn)能徹底「根治」模型幻覺的良方。
那么,大模型究竟為什么會(huì)出現(xiàn)幻覺呢?今天,OpenAI 罕見發(fā)表論文,系統(tǒng)性地揭示了幻覺的根源。
首先,定義幻覺。OpenAI 給出的簡單定義是:「模型自信地生成不真實(shí)答案的情況。」
至于原因,簡單來說就是:標(biāo)準(zhǔn)的訓(xùn)練和評(píng)估程序更傾向于對(duì)猜測進(jìn)行獎(jiǎng)勵(lì),而不是在模型勇于承認(rèn)不確定時(shí)給予獎(jiǎng)勵(lì)。

論文標(biāo)題:Why Language Models Hallucinate
論文地址:https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
下面我們就來具體看看 OpenAI 究竟發(fā)現(xiàn)了什么。
幻覺是語言模型生成的看似合理但卻錯(cuò)誤的陳述。
即使看似簡單的問題,它們也可能以出人意料的方式出現(xiàn)。OpenAI 舉了個(gè)例子,當(dāng)向不同的廣泛使用的聊天機(jī)器人詢問 Adam Tauman Kalai(論文一作)的博士論文標(biāo)題時(shí),它們自信地給出了三個(gè)不同的答案,但沒有一個(gè)是正確的。

當(dāng)詢問他的生日時(shí),它給出了三個(gè)不同的日期,同樣都是錯(cuò)誤的。

OpenAI 表示,幻覺持續(xù)存在,部分原因是當(dāng)前的評(píng)估方法設(shè)置了錯(cuò)誤的激勵(lì)機(jī)制。雖然評(píng)估本身不會(huì)直接導(dǎo)致幻覺,但大多數(shù)評(píng)估模型性能的方式會(huì)鼓勵(lì)模型進(jìn)行猜測,而不是誠實(shí)地面對(duì)不確定性。
可以把它想象成一個(gè)多項(xiàng)選擇題測試。如果你不知道答案,但隨意猜測,你可能會(huì)很幸運(yùn)地猜對(duì)。留空則必定得零分。同樣,當(dāng)模型僅根據(jù)準(zhǔn)確度(即完全答對(duì)問題的百分比)進(jìn)行評(píng)分時(shí),它們會(huì)被鼓勵(lì)進(jìn)行猜測,而不是承認(rèn)「我不知道」。
再舉一個(gè)例子,假設(shè)一個(gè)語言模型被問及某人的生日,但它不知道。如果它猜測「9 月 10 日」,那么它有 1/365 的概率猜對(duì)。說「我不知道」則必定得零分。在數(shù)千道測試題中,猜測型模型最終在記分牌上的表現(xiàn)要優(yōu)于謹(jǐn)慎且承認(rèn)不確定的模型。
對(duì)于只有一個(gè)「正確答案」的問題,可以考慮三類答案:準(zhǔn)確答案、錯(cuò)誤答案以及模型不愿冒險(xiǎn)猜測的棄權(quán)答案。
OpenAI 表示,棄權(quán)答案是謙遜(humility)指標(biāo)的一部分,而謙遜是 OpenAI 的核心價(jià)值觀之一。
大多數(shù)分?jǐn)?shù)指標(biāo)會(huì)根據(jù)準(zhǔn)確度對(duì)模型進(jìn)行優(yōu)先排序,但錯(cuò)誤答案比棄權(quán)答案更糟糕。OpenAI 的模型規(guī)范指出,指出不確定性或要求澄清會(huì)更好,而不是自信地提供可能不正確的信息。
以 GPT5 系統(tǒng)卡中的 SimpleQA 評(píng)估為例。

在準(zhǔn)確度方面,更早期的 OpenAI o4-mini 模型表現(xiàn)略好。然而,其錯(cuò)誤率(即幻覺率)明顯較高。在不確定的情況下進(jìn)行策略性猜測可以提高準(zhǔn)確度,但也會(huì)增加錯(cuò)誤和幻覺。
在對(duì)數(shù)十次評(píng)估的結(jié)果進(jìn)行平均時(shí),大多數(shù)基準(zhǔn)測試都會(huì)剔除準(zhǔn)確度指標(biāo),但這會(huì)導(dǎo)致對(duì)錯(cuò)之間的錯(cuò)誤二分法。
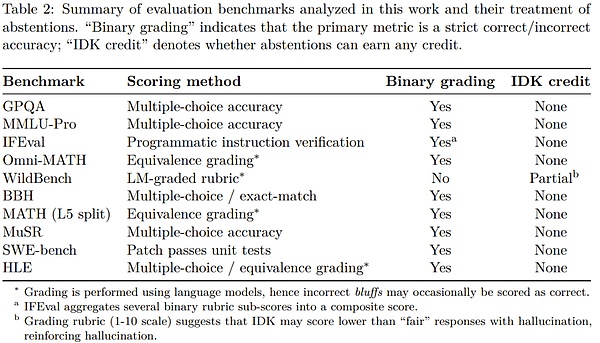
在像 SimpleQA 這樣的簡單評(píng)估中,一些模型的準(zhǔn)確度接近 100%,從而消除了幻覺。然而,在更具挑戰(zhàn)性的評(píng)估和實(shí)際使用中,準(zhǔn)確度會(huì)固定在 100% 以下,因?yàn)橛行﹩栴}的答案由于各種原因(例如信息不可用、小型模型的思維能力有限或需要澄清的歧義)而無法確定。
盡管如此,僅以準(zhǔn)確度為衡量標(biāo)準(zhǔn)的評(píng)估指標(biāo)仍然占據(jù)著排行榜和模型卡的主導(dǎo)地位,這就會(huì)鼓勵(lì)開發(fā)者構(gòu)建能夠猜測而不是退縮的模型。
正因?yàn)榇耍词鼓P妥兊酶酉冗M(jìn),它們?nèi)匀粫?huì)產(chǎn)生幻覺。原因之一便是它們傾向于自信地給出錯(cuò)誤答案,而不是承認(rèn)不確定。
對(duì)此,OpenAI 指出了一個(gè)簡單的解決辦法:對(duì)自信錯(cuò)誤(confidential error)的懲罰力度大于對(duì)不確定性的懲罰力度,并對(duì)恰當(dāng)表達(dá)不確定性的行為給予部分加分。
這個(gè)想法并不新鮮。一些標(biāo)準(zhǔn)化測試長期以來一直使用對(duì)錯(cuò)誤答案進(jìn)行負(fù)面評(píng)分或?qū)α艨諉栴}給予部分加分的方法來阻止盲猜。一些研究團(tuán)隊(duì)也探索了考慮不確定性和校準(zhǔn)的評(píng)估方法。
但 OpenAI 表示,僅僅增加一些新的不確定性感知測試是不夠的。廣泛使用的、基于準(zhǔn)確度的評(píng)估方法需要更新,使其評(píng)分能夠阻止猜測。
如果主要評(píng)估指標(biāo)依然繼續(xù)為模型幸運(yùn)的猜測給予獎(jiǎng)勵(lì),模型就會(huì)繼續(xù)學(xué)習(xí)猜測。修改評(píng)估指標(biāo)可以擴(kuò)大降低幻覺技術(shù)的采用范圍,包括新開發(fā)的和先前研究的技術(shù)。
前面已經(jīng)討論過為什么幻覺如此難以擺脫,但這些高度具體的事實(shí)性錯(cuò)誤究竟從何而來?
畢竟,大型預(yù)訓(xùn)練模型很少出現(xiàn)其他類型的錯(cuò)誤,例如拼寫錯(cuò)誤和括號(hào)不匹配。
OpenAI 表示,區(qū)別必定在于數(shù)據(jù)中存在哪些模式。
語言模型首先通過預(yù)訓(xùn)練進(jìn)行學(xué)習(xí),這是一個(gè)預(yù)測海量文本中下一個(gè)詞的過程。
與傳統(tǒng)的機(jī)器學(xué)習(xí)問題不同,每個(gè)語句沒有「真 / 假」標(biāo)簽。該模型只看到流暢語言的正面示例,并且必須去近似整體分布。
當(dāng)沒有任何被標(biāo)注為無效的示例時(shí),區(qū)分有效語句和無效語句會(huì)更加困難。但即使有標(biāo)簽,一些錯(cuò)誤也是不可避免的。
為了理解原因,可以考慮一個(gè)更簡單的類比。在圖像識(shí)別中,如果數(shù)百萬張貓狗照片被標(biāo)記為「貓」或「狗」,算法可以學(xué)會(huì)可靠地對(duì)它們進(jìn)行分類。但想象一下,如果用寵物的生日來標(biāo)記每張寵物照片。由于生日本質(zhì)上是隨機(jī)的,無論算法多么先進(jìn),這項(xiàng)任務(wù)總是會(huì)產(chǎn)生錯(cuò)誤。
同樣的原則也適用于預(yù)訓(xùn)練。拼寫和括號(hào)遵循一致的模式,因此這些錯(cuò)誤會(huì)隨著規(guī)模的擴(kuò)大而消失。但像寵物的生日這樣任意的低頻事實(shí),無法僅憑模式預(yù)測,因此會(huì)導(dǎo)致幻覺。
OpenAI 的分析解釋了哪些類型的幻覺會(huì)由下一個(gè)詞預(yù)測產(chǎn)生。理想情況下,預(yù)訓(xùn)練后的后續(xù)階段應(yīng)該能夠消除這些幻覺,但由于上一節(jié)中描述的原因,這并未完全實(shí)現(xiàn)。
OpenAI 表示:「我們希望本文中的統(tǒng)計(jì)學(xué)視角能夠闡明幻覺的本質(zhì),并駁斥一些常見的誤解」:
有人宣稱:幻覺可以通過提高準(zhǔn)確度來消除,因?yàn)?100% 準(zhǔn)確的模型永遠(yuǎn)不會(huì)產(chǎn)生幻覺。
發(fā)現(xiàn):準(zhǔn)確度永遠(yuǎn)不會(huì)達(dá)到 100%,因?yàn)闊o論模型規(guī)模、搜索和推理能力如何,有些現(xiàn)實(shí)世界的問題本質(zhì)上是無法回答的。
有人宣稱:幻覺是不可避免的。
發(fā)現(xiàn):幻覺并非不可避免,因?yàn)檎Z言模型在不確定時(shí)可以放棄回答。
有人宣稱:避免幻覺需要一定程度的智能,而這只有大型模型才能實(shí)現(xiàn)。
發(fā)現(xiàn):小型模型更容易了解自身的局限性。例如,當(dāng)被要求回答毛利語問題時(shí),一個(gè)不懂毛利語的小型模型可以直接回答「我不知道」,而一個(gè)認(rèn)識(shí)一些毛利語的模型則必須確定其置信度。正如論文中所討論的,「校準(zhǔn)」所需的計(jì)算量遠(yuǎn)小于保持準(zhǔn)確。
有人宣稱:幻覺是現(xiàn)代語言模型的一個(gè)神秘缺陷。
發(fā)現(xiàn):我們可以理解幻覺產(chǎn)生以及在評(píng)估中獲得獎(jiǎng)勵(lì)的統(tǒng)計(jì)學(xué)機(jī)制。
有人宣稱:要測量幻覺,我們只需要一個(gè)好的幻覺評(píng)估。
發(fā)現(xiàn):已有研究者發(fā)表了一些幻覺評(píng)估。然而,一個(gè)好的幻覺評(píng)估與數(shù)百種傳統(tǒng)的基于準(zhǔn)確度的評(píng)估相比幾乎沒有效果,這些評(píng)估會(huì)懲罰謙遜并獎(jiǎng)勵(lì)猜測。相反,所有主要的評(píng)估指標(biāo)都需要重新設(shè)計(jì),以獎(jiǎng)勵(lì)不確定性的表達(dá)。
OpenAI 表示:「我們最新的模型幻覺率更低,并且我們將繼續(xù)努力,進(jìn)一步降低語言模型輸出的置信錯(cuò)誤率。」
順帶一提,據(jù) TechCrunch 報(bào)道,OpenAI 正在重組其模型行為(Model Behavior)團(tuán)隊(duì),這是一支規(guī)模雖小但頗具影響力的研究人員團(tuán)隊(duì),他們決定著該公司的 AI 模型與人互動(dòng)的方式。現(xiàn)在,該團(tuán)隊(duì)將向 OpenAI 的后期訓(xùn)練主管 Max Schwarzer 匯報(bào)。
而該團(tuán)隊(duì)的創(chuàng)始負(fù)責(zé)人 Joanne Jang 則將在公司啟動(dòng)一個(gè)新項(xiàng)目,名為 oai Labs。據(jù)她的推文介紹:「這是一個(gè)以研究為導(dǎo)向的團(tuán)隊(duì),專注于發(fā)明和設(shè)計(jì)人們與 AI 協(xié)作的新界面原型。」

<strike id="ykeqq"></strike>
<fieldset id="ykeqq"></fieldset>
 喜來順財(cái)經(jīng)
喜來順財(cái)經(jīng)